Contrôler le placement d’un job hybride
Il est particulièrement important de contrôler le placement de ses threads dans le cas d’un job hybride (openmp + mpi).
Cas d’utilisation : Un exécutable mpi sur Olympe utilise 4 processus par nœud, chaque processus utilise 8 threads. On souhaite que chaque processeur d’Olympe exécute deux processus, 16 cœurs de calcul seront donc utilisés sur chaque processeur.
Vérifier ce qui va se passer (en théorie) :
# placement 4 8 --ascii S0---------------- S1---------------- P AAAAAAAABBBBBBBB.. CCCCCCCCDDDDDDDD..
- Le premier paramètre (
4) est le nombre de processus - Le second paramètre (
8) est le nombre de threads par processus - Le switch (
--ascii) entraîne un affichage en "art ascii", c’est-à-dire une représentation visuelle du placement sur les deux processeurs, uniquement pour un contrôle rapide.
Générer les switches qui vont bien pour srun :
# placement 4 8 --srun --cpu_bind=mask_cpu:0xff,0xff00,0x3fc0000,0x3fc000000
- Les deux premiers paramètres sont inchangés
- Le switch
--srunprovoque la sortie compatible avec le contrôle du placement pour srun. - la sortie par défaut de
placement.
Insérer la commande placement dans le script sbatch:
# srun $(placement) mon_executable ...
- Les paramètres
4et8sont superflus à condition que la réservation slurm ait été faite correctement, avec les balises#SBATCH --tasks_per_nodeet#SBATCH --cpus_per_task - Le switch --srun est superflu car la sortie "srun" est la sortie par défaut de placement
- La syntaxe
bash $()remplace ce qui est à l’intérieur des parenthèses par la sortie de la commande, donc srun voit simplement les switches de contrôle du placement.
Vérifier que le placement est correct:
Lorsque le job est en exécution, il est utile de vérifier que le placement est correct :
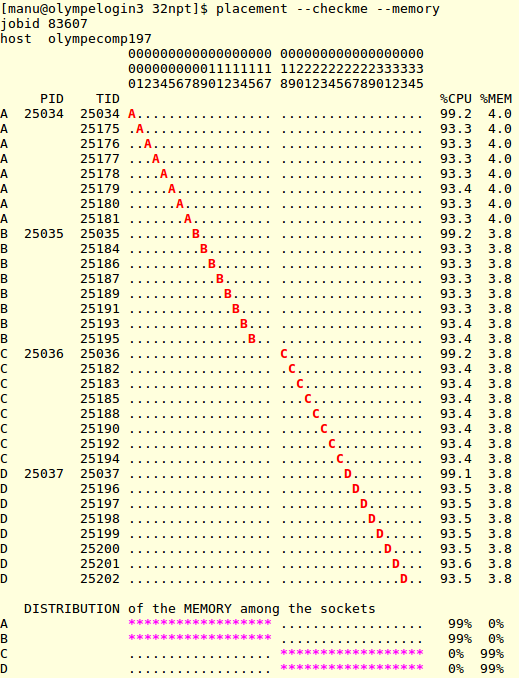
On voit ici que :
- Le placement des threads de chaque processus correspond à ce que l’on souhaite
- La mémoire des processus est allouée sur les bancs connectés au bon processeur
Vérifier le placement sur tous les nœuds utilisés
La commande ci-dessus ne vous montrera que l'état du premier nœud utilisé par votre job: par défaut placement considère que la situation sera la même sur tous les nœuds, et simplifie l'affichage en conséquence. Dans certains cas on peut cependant souhaiter vérifier ce qui se passe sur tous les nœuds utilisés par notre job. La commande suivante permet de faire cela:
placement --host=$(squeue -j xxxxxx -h -o %N)
Vérifier l’utilisation du GPU
Lorsqu’un job est exécuté sur un nœud GPU il est également utile de vérifier que les GPUSs sont effectivement utilisés :
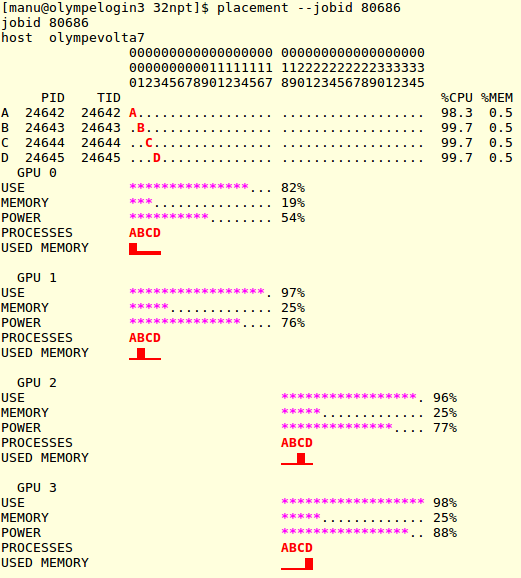
On voit ici que :
- Les quatre GPUs du nœud sont utilisés
- Les processus A,B,C,D communiqueront chacun avec un GPU
- Le placement des processus C et D n’est pas optimal puisqu’ils doivent communiquer avec les GPUs se trouvant connectés sur un autre CPU que celui sur lequel ils tournent. [36]
La documentation de placement
La documentation complète de placement peut se lire par :
placement --documentation
L’aide rapide est accessible par :
placement --help
On peut trouver d’autres informations sur le wiki de placement